Créez facilement des personnalités d'IA uniques avec Ollama
"huggingface", faire un câlin à quoi ?
Nommé d'après l'emoji 🤗, je suppose que sans l'apport de trop nombreux consultants en stratégie de marque, Hugging Face peut être considéré comme le « GitHub de l'IA ». À la base, il héberge des référentiels contenant des modèles et des ensembles de données pour le traitement du langage naturel, la vision par ordinateur, l'audio et tout ce qui a trait à l'apprentissage automatique.
En outre, Hugging Face permet aux utilisateurs de publier des messages et des discussions, offre des services de calcul pour entraîner et affiner vos propres modèles, et dispose d'une fonction appelée « Spaces » qui permet à sa communauté d'exécuter des applications et des services liés à l'apprentissage automatique sur leur infrastructure. Il existe également Hugging Chat, un service similaire à ChatGPT qui utilise exclusivement des LLM open source.
Si l'on met tout cela bout à bout, Hugging Face peut être un endroit intimidant à parcourir pour les non-initiés. Mais il s'agit sans aucun doute d'un lieu actif et vivant, et pour tous ceux qui veulent avoir quelque chose à voir avec l'IA, c'est ici que tout se passe !
Naviguer dans le monde sauvage des LLM
Pour s'y retrouver dans la myriade de nouveaux modèles qui apparaissent constamment sur Hugging Face, il faut d'abord prendre un peu de recul et comprendre la structure de cet écosystème LLM à source ouverte.
Modèles de base
La création d'un nouveau LLM à partir de zéro est une opération complexe et gourmande en ressources informatiques. Nous savons que la formation du Llama 2 a nécessité l'utilisation de 6 000 GPU pendant deux semaines, pour un coût d'environ 2 millions de dollars. Quelques grandes entreprises technologiques et sociétés de recherche en IA bien financées se livrent à ce genre d'exercice au grand jour, notamment
Meta - créateurs des modèles Llama 2
Mistral AI - à l'origine des modèles Mistral et Mixtral
01.ai - société chinoise à l'origine des modèles Yi
Upstage AI - créateurs des modèles Solar
Le Llama 2 n'est pas un modèle unique : il existe en plusieurs tailles : 7b, 13b et 70b. Il s'agit du nombre de paramètres (également appelés poids) sur lesquels le modèle a été entraîné. Une plus grande taille signifie plus de paramètres et, en général, cela devrait se traduire par un modèle plus performant, plus intelligent et mieux informé, mais qui nécessite plus de ressources système pour fonctionner.
En outre, le Llama 2 existe en deux variantes : le modèle de base et une version « chat ». Que se passe-t-il donc ici ?
N'oubliez pas qu'un LLM est un modèle de langage formé pour « compléter » un texte. Par exemple, si vous écrivez une invite « Je me suis réveillé le matin et... », le modèle de base complétera cette phrase par quelque chose comme « ... peigné mes cheveux, brossé mes dents et préparé la journée à venir ». C'est tout ce que fait le modèle : comprendre le contexte d'une invite et générer une séquence de mots statistiquement probable pour compléter le modèle, sur la base de ses données d'entraînement.
La création d'un modèle avec lequel vous pouvez discuter et avoir des conversations à bâtons rompus nécessite un entraînement plus poussé et un réglage plus fin, à l'aide d'ensembles de données de discussions et de questions-réponses. Le résultat est un modèle optimisé pour le « chat ». Maintenant, si vous lui posez une question ou si vous lui fournissez un historique de messages et de réponses, le LLM est mieux formé pour répondre avec le message suivant dans le chat. Il fait toujours fondamentalement la même chose - compléter l'invite avec un modèle statistiquement probable basé sur son entraînement - mais cet entraînement lui permet de reconnaître que le texte qu'il doit générer est le message suivant dans une séquence de messages.
Vous trouverez d'autres variantes comme « instruire », qui signifie que le modèle de base a été entraîné sur des ensembles de données d'instruction, comme « aidez-moi à relire ceci » ou « écrivez un brouillon pour cela ». C'est le même principe, mais l'entraînement est légèrement différent.
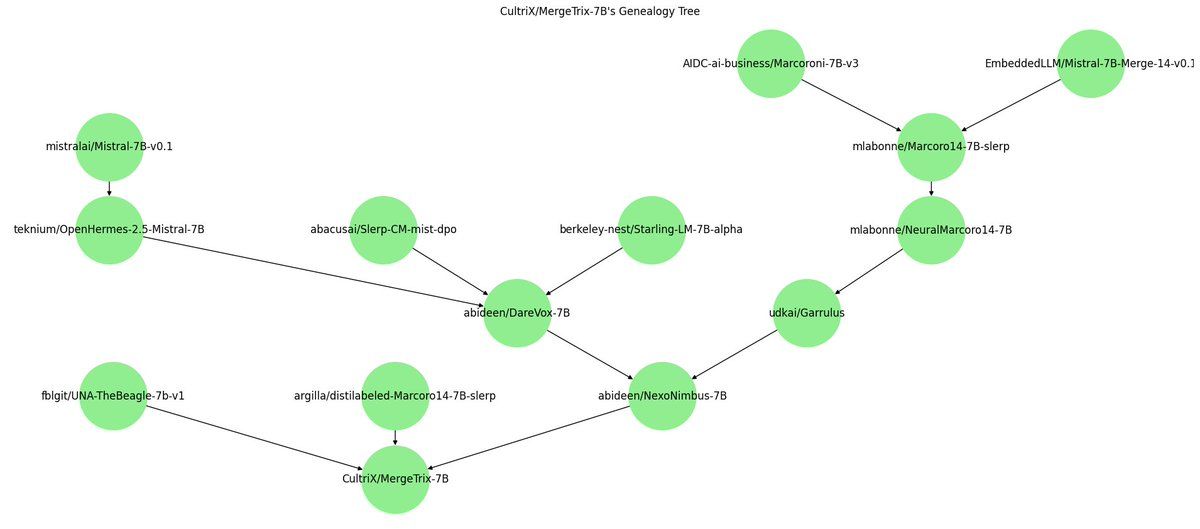
Fusionner des modèles
OK, jusqu'ici tout va bien ? Nous avons quelques entreprises technologiques et sociétés de recherche qui créent de nouveaux LLM. Ils sont généralement de tailles différentes et ont parfois des variations qui reflètent une formation supplémentaire et un réglage fin. Cherchez donc « llama 7b » sur Hugging Face - allez-y, essayez maintenant. Vous ne trouverez pas 2 ou 3 variations différentes, mais plus de 8 000 modèles différents. Alors, pourquoi tous ces lamas ?
C'est là que la communauté de Hugging Face entre en jeu. Laissez de côté les entreprises technologiques bien financées, et entrez dans la danse des amateurs, des passionnés et des marginaux de l'IA. Si la formation d'un LLM entièrement nouveau est hors de portée de la plupart des individus, ce n'est pas le cas pour le réglage fin. Si vous avez quelques vieux GPU qui traînent depuis vos années de minage de crypto-monnaie, ou si vous êtes prêt à dépenser quelques dollars pour faire tourner quelques GPU en nuage pendant une courte période, alors vous êtes tout à fait capable de créer vos propres LLM en prenant un modèle de base ouvert, et en le fusionnant avec d'autres modèles ou en l'affinant avec différents ensembles de données ouverts. C'est ce que la communauté Hugging Face fait avec enthousiasme. Connus sous le nom de « Franken-merges », ces modèles sont plus nombreux que vous ne pourrez jamais en suivre l'évolution, qu'il s'agisse de modèles formés à des fins médicales, philosophiques ou d'aide aux relations personnelles, de modèles non censurés et impartiaux, ou encore de nombreux (je dis bien nombreux) modèles conçus pour les jeux de rôle érotiques.
En fin de compte, cela crée une structure arborescente de LLM, qui n'est pas sans rappeler l'écosystème Linux. Au sommet se trouvent quelques modèles de base, à partir desquels est dérivée une famille riche et variée de modèles interdépendants et dépendants.
Formats et niveaux de quantification
Il y a une autre pièce du puzzle qu'il nous faut comprendre. Pour exécuter les modèles distribués par les créateurs originaux, il faut généralement utiliser Transformers (une bibliothèque Hugging Face) et écrire manuellement du code en Python. Pour utiliser le modèle avec Ollama, nous avons besoin d'une version « quantifiée ». De nombreux modèles disponibles sur Hugging Face sont en fait des versions quantifiées de modèles existants fournis par différents membres de la communauté.
La quantification est un moyen de représenter les paramètres d'un modèle avec moins de bits. En réduisant la taille de chaque paramètre, le modèle devient plus petit et nécessite moins de mémoire, mais au prix de l'exactitude et de la précision.
C'est comme si vous réduisiez la résolution d'une photographie. Vous pouvez utiliser un outil comme Photoshop pour réduire la résolution d'une image de 10 ou 20 % et réduire la taille du fichier sans perdre trop de qualité et de détails. Mais si vous allez trop loin et réduisez la résolution de manière trop radicale, l'image perd de sa clarté. Il en va de même pour la quantification - l'objectif est de trouver un juste milieu qui rende le LLM plus accessible à une plus large gamme de matériel, tout en veillant à ce que la baisse de qualité reste tolérable.

l y a quelques formats différents de quantification que vous remarquerez en parcourant Hugging Face. GPTQ (GPT Post Training Quantisation) et AWQ (Activation-aware Weight Quantisation) sont deux formats qui se concentrent principalement sur l'inférence et les performances du GPU. Bien que ces formats soient très performants, l'accent mis sur le GPU est un inconvénient si vous ne disposez pas du matériel nécessaire pour les faire fonctionner. C'est là qu'intervient le format GGUF (GPT-Generated Unified Format). Le format GGUF, utilisé par Ollama, est une méthode de quantification qui utilise l'unité centrale pour exécuter le modèle, mais qui décharge également certaines de ses couches sur le GPU pour accélérer le processus.
Pour approfondir la quantification, je vous recommande vivement d'ajouter à votre liste de lecture l'excellent article de Maarten Grootendorst sur les méthodes de quantification.
Une dernière chose à garder à l'esprit est que les GGUFs eux-mêmes sont de formes et de tailles différentes. Les noms de modèles avec le suffixe Q3_0, Q4_0, Q5_0 et Q6_0 font référence au niveau de quantification. Q3 correspond à une quantification de 3 bits et Q6 à 6 bits. Plus le nombre est faible, plus la compression est importante et plus la perte de précision et d'exactitude est grande. Entre ces niveaux de quantification, on peut observer des étapes plus fines comme K_S, K_M et K_L (petit, moyen et grand). Les quantifications de niveau K permettent généralement d'obtenir le meilleur compromis entre la taille et la qualité.
Je sais, c'est compliqué. J'essaie généralement de trouver le modèle le plus grand qui fonctionnera confortablement sur ma machine (Mac Studio M1 Max 32 GB). Pour les modèles 7b-13b, je cherche un Q5_K_M, et pour les modèles 34b, je passe à un Q4_K_M ou même à un Q3 si nécessaire. En fonction de votre propre système, YMMV.
Décodage des noms de fichiers de modèles
Cette section a été une longue façon de dire qu'il y a BEAUCOUP de modèles sur lesquels gaspiller votre bande passante ! En parcourant Hugging Face, vous trouverez de nombreux modèles avec des noms de fichiers longs et archaïques. Bien qu'il n'y ait pas de convention d'appellation standard, j'espère que vous commencerez à reconnaître que les auteurs utilisent des modèles dans leurs noms de fichiers.
Par exemple, CapybaraHermes-2.5-Mistral-7B-GGUF indique que le modèle de base est Mistral 7B, qu'il a été affiné avec les jeux de données Capybara et OpenHermes et qu'il s'agit d'une version quantifiée GGUF. Une fois que vous aurez téléchargé quelques modèles et lu quelques fiches de modèle, tout cela commencera à prendre un sens.
Trouver des modèles intéressants
Je vous recommande de suivre le site /r/LocalLLaMA, qui propose souvent des discussions sur les nouveaux modèles, et je vous déconseille de prêter trop d'attention aux différents classements sur les espaces Hugging Face, qui sont facilement jouables en effectuant des réglages spécifiques pour le classement. Pour les modèles qui sortent des sentiers battus, assurez-vous de suivre TheBloke et LoneStriker qui produisent de manière prolifique des quants GGUF pour toutes sortes de modèles peu connus.
Découverte de LLM moins connus avec Hugging Face
Libre LLM